Interactive bucketing¶
You might want to manually edit the bucketing boundaries, for example to incorporate specific domain knowledge. You can manually define buckets, but you could also use to interactive explore and update the buckets. All skorecard.bucketers have a method called .fit_interactive(), which will call .fit() if the bucketer is not yet fitted, and then launch a dash webapp.
Make sure to have the up to date dash dependencies by running pip install --upgrade skorecard[dashboard].
from skorecard.datasets import load_uci_credit_card
from skorecard.bucketers import DecisionTreeBucketer
X, y = load_uci_credit_card(return_X_y=True)
bucketer = DecisionTreeBucketer(max_n_bins=10)
# bucketer.fit_interactive(X, y) # not run
This should look like:
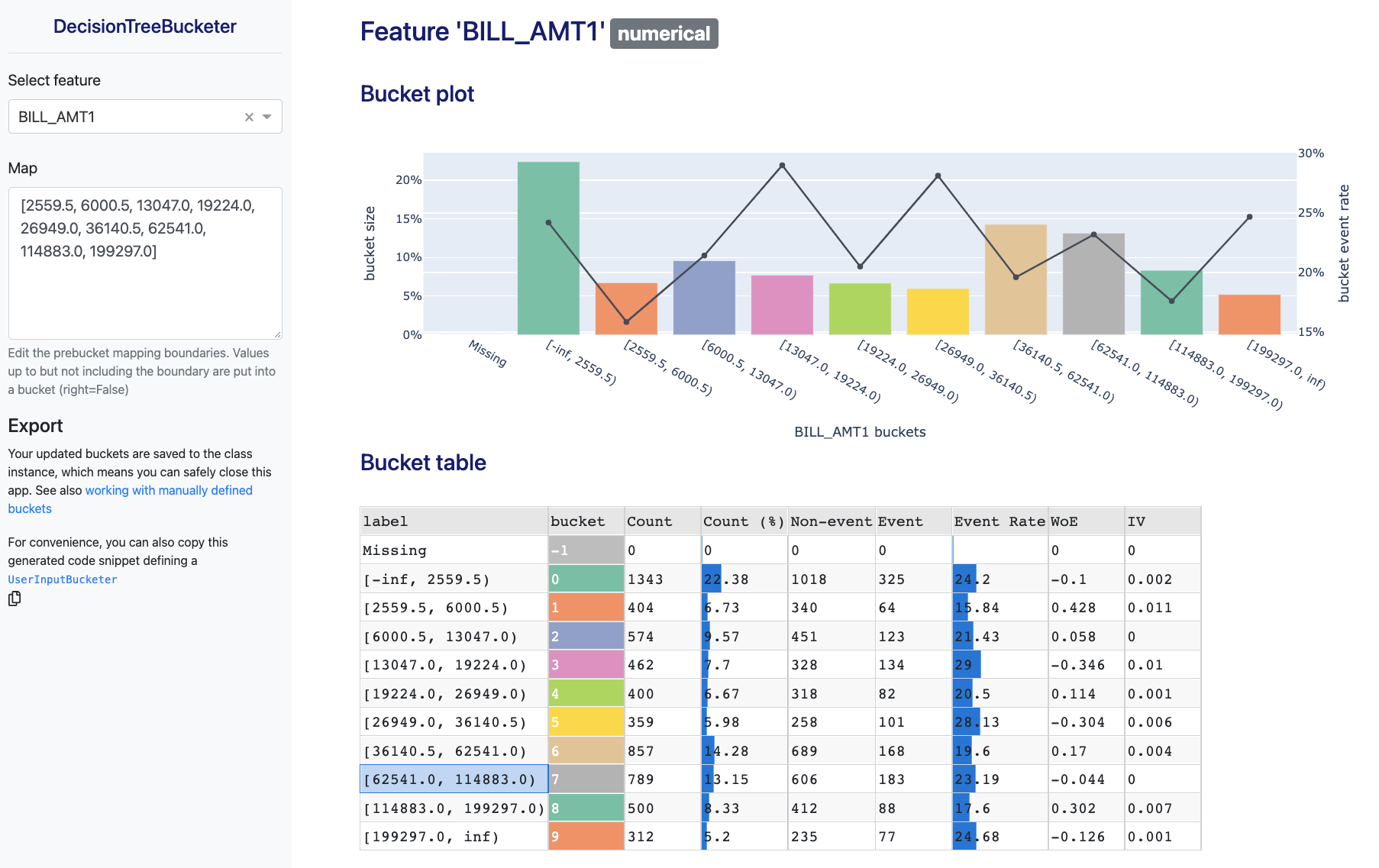
This also works for categorical features:
from skorecard.bucketers import OrdinalCategoricalBucketer
import random
pets = ["no pets"] * 3000 + ["cat lover"] * 1500 + ["dog lover"] * 1000 + ["rabbit"] * 498 + ["gold fish"] * 2
random.Random(42).shuffle(pets)
X["pet_ownership"] = pets
bucketer = OrdinalCategoricalBucketer(variables=["pet_ownership"])
# bucketer.fit_interactive(X, y) # not run
Which should look like:
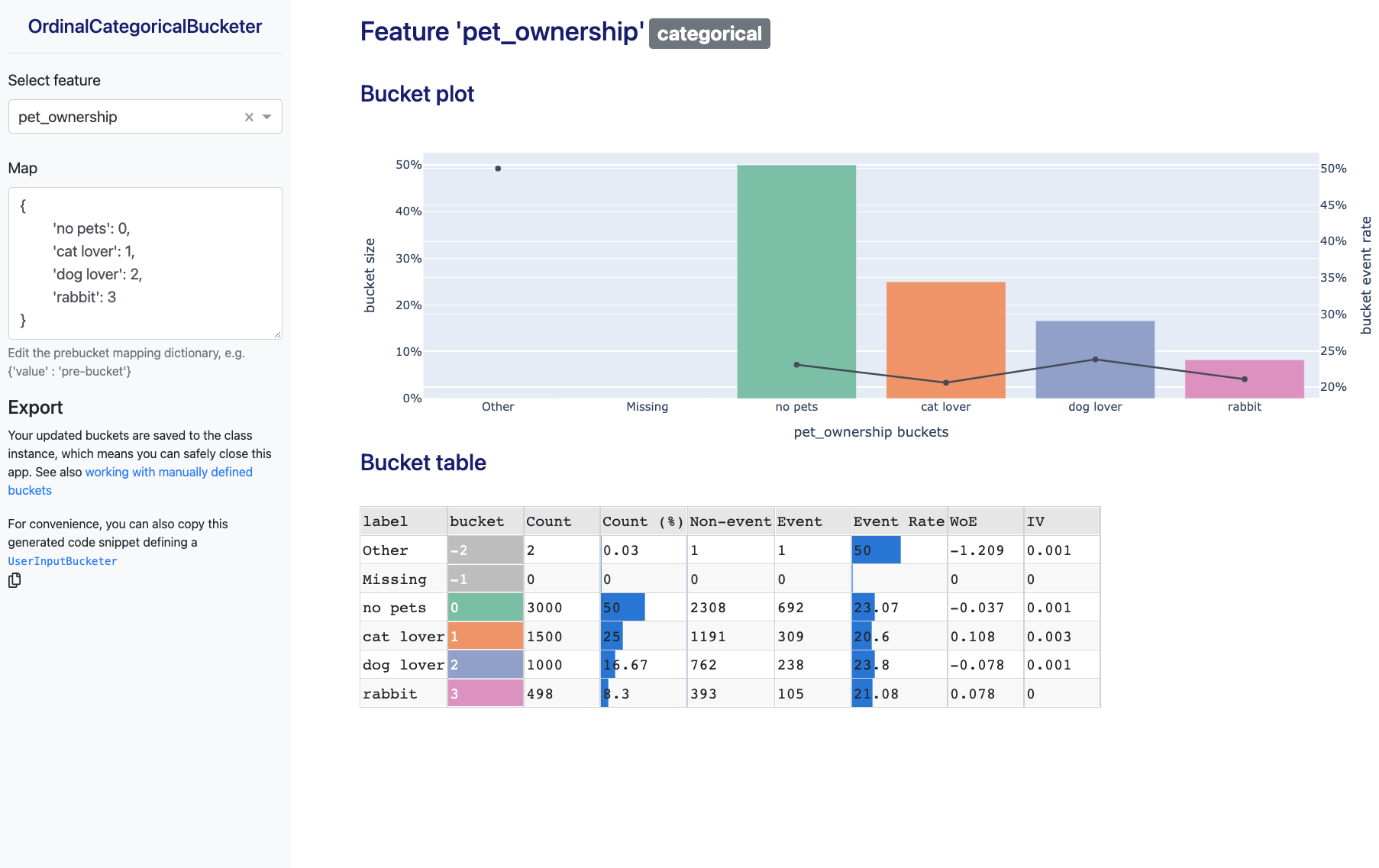
Pipelines¶
You can also run .fit_interactive() on a pipeline of bucketers. You'll need to convert to a SkorecardPipeline in order to have access to the method:
from skorecard.bucketers import OrdinalCategoricalBucketer
from skorecard.pipeline import to_skorecard_pipeline
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OrdinalCategoricalBucketer(variables=["EDUCATION", "MARRIAGE"]),
DecisionTreeBucketer(max_n_bins=10, variables=["LIMIT_BAL", "BILL_AMT1"]),
)
# Make this a skorecard pipeline, which adds some convenience methods
pipe = to_skorecard_pipeline(pipe)
# pipe.fit_interactive(X, y) # not run
BucketingProcess and Skorecard models¶
Interactively setting pre-bucketing and bucketing per column is also possible on BucketingProcess and Skorecard models
from skorecard import Skorecard
from skorecard.datasets import load_uci_credit_card
model = Skorecard(variables=["EDUCATION", "MARRIAGE", "LIMIT_BAL", "BILL_AMT1"])
# model.fit_interactive(X, y) # not run